Evaluating LLMs - Notes on a NeurIPS'24 Tutorial

I attended NeurIPS’24 virtually, and I was happy to see that they had two tutorials on topics that I care about. One was on evaluating LLMs, and the other one was on decoding-time strategies. This post covers the former. I have been meaning to publish this for a while, but this languished as a draft for a long time while life got in the way. Well.
- Introduction
- Tutorial Intro - Irina Sigler
- Quality Evaluation - Yuan Xue (talk), Irina Sigler (code)
- Conclusion
- References
Note: Of the three talk sections, I don’t cover “Safety Evaluations”, presented by Bo Li.
Introduction
This was a ~3 hr session by staff at Google AI - here are the slides. Just before publishing this post I discovered that the presenters have distilled the tutorial content into a whitepaper which also links to colab notebooks. The tutorial was well done and I often found myself nodding along with what the speakers had to say. This is an important topic to me, and is increasingly receiving general attention: now that prototyping AI solutions has become simpler, the burden of rolling out a reliable product had shifted to the testing phase. It is easy to build something, but how can you be sure that it is the something that you wanted? Especially since LLMs can be sneaky: it is easy to end up with a false sense of confidence with them.
Answer: rigorous evaluations. I am reminded a bit of D. Richard Hipp - primary author of SQLite - who heavily credits testing for their overwhelming success. As of writing this, their test-suite has 590x more code than the SQLite codebase itself.
LLMs are an outstanding achievement. As of writing this, I have been working on Natural Language Processing (NLP) and associated areas for 17 years, and frankly, good Natural Language Generation (NLG) has been the proverbial thorn in the side for NLP practitioners. Till recently that is - when ChatGPT signaled an inflection point (or around that time, depending on what you consider the start, e.g., maybe the Transformers paper?) . It makes the academic and the hobbyist in me happy, but as someone building software systems, I still am a skeptoptimist (skeptical optimist). LLM-based systems often easily pass “vibe checks” (I recently came across VibeCheck (Dunlap et al., 2025) - a library to quantify difference in LLMs - yes, the joke is on me)- they’re convincing on a handful of examples - but then reveal surprising failure modes on wider validation. This is in contrast to earlier, where such anecdotal checks were often unconvincing, and the struggle to socialize your solution was different: you had to appeal to gross performance to appease critics, e.g., “Look this is right 80% of time - you need to try a lot of examples to know - and it is more scalable than humans! (we often didn’t/couldn’t make an argument for accuracy wrt humans)”. We need to equip ourselves for this new world.
It is important to recognize that with LLMs the model “blackbox-ness” problem has not gone away. Let it not fool you that you can communicate with them in natural language. That’s the interface, and sure, that lowers the barrier of entry for their use, but then we inherit its lack of precision. Also the interface doesn’t tell you about the inner workings of a model.
As as an aside, why do we have a problem with evaluations now? Well, it has always been hard to validate NLG. But since we didn’t have widespread good NLG systems prior to the ChatGPT-era, this didn’t register broadly as an area needing attention. The sudden leap-frogging to high-quality NLG has left validation techniques behind. And its popularity has highlighted this gap.
To put it bluntly: earlier NLG systems weren’t good enough for widespread use, and therefore didn’t warrant this level of attention.
Let’s get started. I will summarize the session here, while interleaving my opinions which I’ll call out. Direct quotes from the presenters or the slides are in this color.

Tutorial Intro - Irina Sigler
Previously, there was a lot of work involved in building a Minimum Viable Product (MVP) - collect the right data, possibly label, train models, etc., but today, that part is made extremely convenient by LLMs, and the real work begins post MVP. For ex., the MVP might have seemed convincing with a few prompts, but with real users, you want an effective and reliable prompt template. There are other decisions to be made past the MVP stage: do you have the right model, should you use a distilled version, fine-tune vs RAG, etc.
A good evaluation framework is important in guiding such decision making. It prevents you from confidently marching into the wrong direction. In the table below, rows show the broader axes to keep in mind when coming up with an evaluation framework, with columns providing additional detail. There is no strict ordering in terms of rigor, or when in a product life-cycle an item applies, in moving from left to right across the columns for a row. Look out for highlighted text in the table - these are links.
| 1. Use Case: Ensure coverage of prompts that various user actions can produce. [AG] This is like the "data scope", where data now is the set of prompts user actions might trigger. |
A. Manual. Think up some prompts, involve your team, your domain expert - more the better! |
B. Synthetic. Use the LLM to augment the scenario data you already have. But it is advised to perform the previous step first. |
C. Traffic. Use actual production data to validate your system. In other words, keep refining your tests based on data that you log. [AG] As always, the ultimate litmus test. But necessary especially today, since airtight offline testing of LLM-based systems might not be possible due to the innate variability of natural language. So we need to keep looking out for things that fail during actual use. |
| 2. Context: To what view of the system does a test apply? |
A. Final. You want to test the output of the whole system, or the "final" output the given an input. This is not the input/output for the LLM. |
B. Intermediate. As your system grows, e.g., maybe you now have a RAG system, a cache, etc., you might want to perform component-wise evaluation, for insights or just in the interest of granular debugging. For ex., using NDCG to evaluate RAG. |
C. Trajectory. Instead of treating the components independently, you want to look the trajectory of components an input touches, and the corresponding outputs. [AG] I don't know how practical this is in a system that has a high branching factor in going from one component to the next. Might be feasible for a small number of examples. |
| 3. Criteria: Metrics. |
A. Similarity. These metrics are easy to compute but can be inaccurate, e.g, embeddings-based similarity scores such as SemScore. They may not capture nuances, leading to clearing inaccurate responses or penalizing valid ones. But OK to use as long as people are aware of this limitation. [AG] Also, sometimes a good "first-level" validation since they may be done at scale. But yes, can be tricky. You need to think hard about what is considered "pass". |
B. Criteria per task. For certain attributes, it is helpful to break them down to smaller factors that are relatively easier to test or agree upon. [AG] For example, if you want to assign a quality score to a student essay, you might also want to provide a break-up of what worked well, or didn't, across pre-defined axes such as "prose quality", "verbosity", etc. LLM-based metrics such as G-Eval are useful for such setups. |
C. Rubrics per data point. You might have bespoke criteria per input/output which need to be validated. [AG] To take the example of essay grading again, maybe the grading criteria differ, or the relative weights of criteria differ, based on the topic. For ex., we might want essays on AI to discuss ethical concerns - something that may not apply to other topics. And again, techniques like G-Eval are useful here. |
Here’s a rephrased version for something the presenter said - and something I’ve been saying for a while: previously models were built for specific tasks/data, which we would then try to generalize for broader use-cases. Like a widening funnel if you will. Today, we start with a highly general model - trained on the entire Internet’s worth of data - and then try to focus it on the task at hand. A narrowing funnel. So, it shouldn’t be surprising that evaluations need to change - from detecting a model from doing too less to doing too much, e.g., hallucinations.
There is one silver lining in all this: the new metrics are easily expressible in plain English. For ex., it is easy to understand (broadly) what we want to measure with “fluency”. Contrast this to the earlier era, where metrics would be hard to explain to a layperson. This rings true wrt my personal experience - today we talk about “coherence” and “fluency” as opposed to F1-score, AUC, entropy. It is hard to know how we are going to measure something like “coherence”, but it is (somewhat) clear what we want to measure.
Resources: The Measuring Massive Multitask Language Understanding (MMLU) and Chatbot Arena (formerly LMSYS) benchmarks were mentioned as examples of general benchmarks that do not directly tell you about how LLMs would do on your specific task. This diagram by Chip Huyen was used to show what a real-world GenAI platform might look like. Personally, I have known GenAI stacks to get far more complex. The EvalLM paper (Kim et al., 2024) was cited which discusses how designers iterate over prompts (based on interviews), and how criteria-based automated evaluations may be used in practice. The problem of criteria refinement was also briefly discussed (Shankar et al., 2024); this is when a designer modifies their criteria based on grading some outputs (a very real phenomena in my opinion). The cited paper calls it criteria drift and proposes a framework called EVALGEN to aid the refinement process.
Quality Evaluation - Yuan Xue (talk), Irina Sigler (code)
This part was a deep-dive into methodologies of evaluation. Here, I will mention the resources in text.
Scope of Evaluation
The task of evaluation in a general sense was discussed first. This may be concisely represented as:
\(F(\text{subject}, \text{criteria}, \text{reference}^*) \rightarrow \text{result}\).
Here,
- subject is what we want to evaluate.
- criteria are evaluation criteria.
- result is the evaluation itself, which may be accompanied by explanations.
- reference is optional, and is provided if the criteria needs to compare to some form of ground truth. For ex., in a summarization task, a sample ground-truth summary, or a few such summaries, might be provided.
Consider the subject first. Since we are evaluating LLMs (or possibly Agent systems), we are going to look at the combination of prompt and response as the subject. Note here that the prompt is not just your query to the LLM, but also context, e.g., demonstrations, documents from a RAG system. The two common kinds of subjects are:
- Point-wise. We are rating a prompt and corresponding response as input, and we require an absolute score. Also known as direct assessment.
- Pair-wise. We ask for a comparison between two responses for the same prompt. Presumably one response is a baseline, e.g., one might be a human response and the other an LLM-generated one. [AG] - if you’re a ChatGPT user, you’re probably familiar with this - sometimes you’re asked to pick between two responses.
The following image shows the two kinds of subjects. From the Prometheus 2 open Language Model evaluator (Kim et al., 2024).
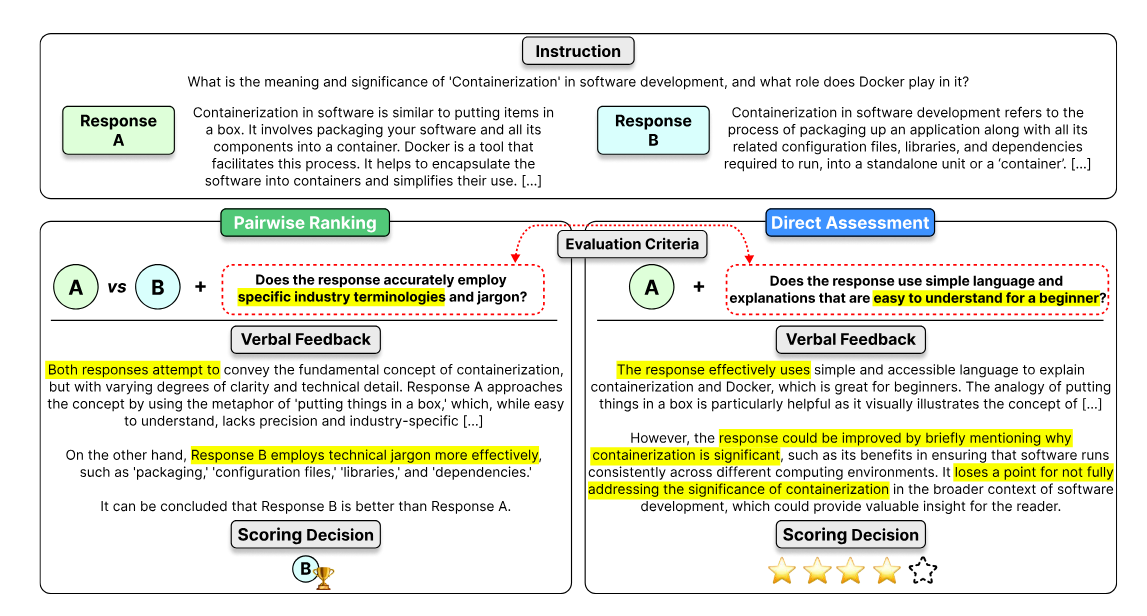
Two kinds of subjects. Source.
Moving onto the criteria, the two key parts are:
- Aspect or dimension of evaluation: These can be general criteria like coherence and fluency, but also task-specific ones like groundedness for a RAG system. Of course, there might be task specific ones as well such as following a specific tone that’s representative of a company or a demographic. Radar charts such as the one below are a convenient representation:
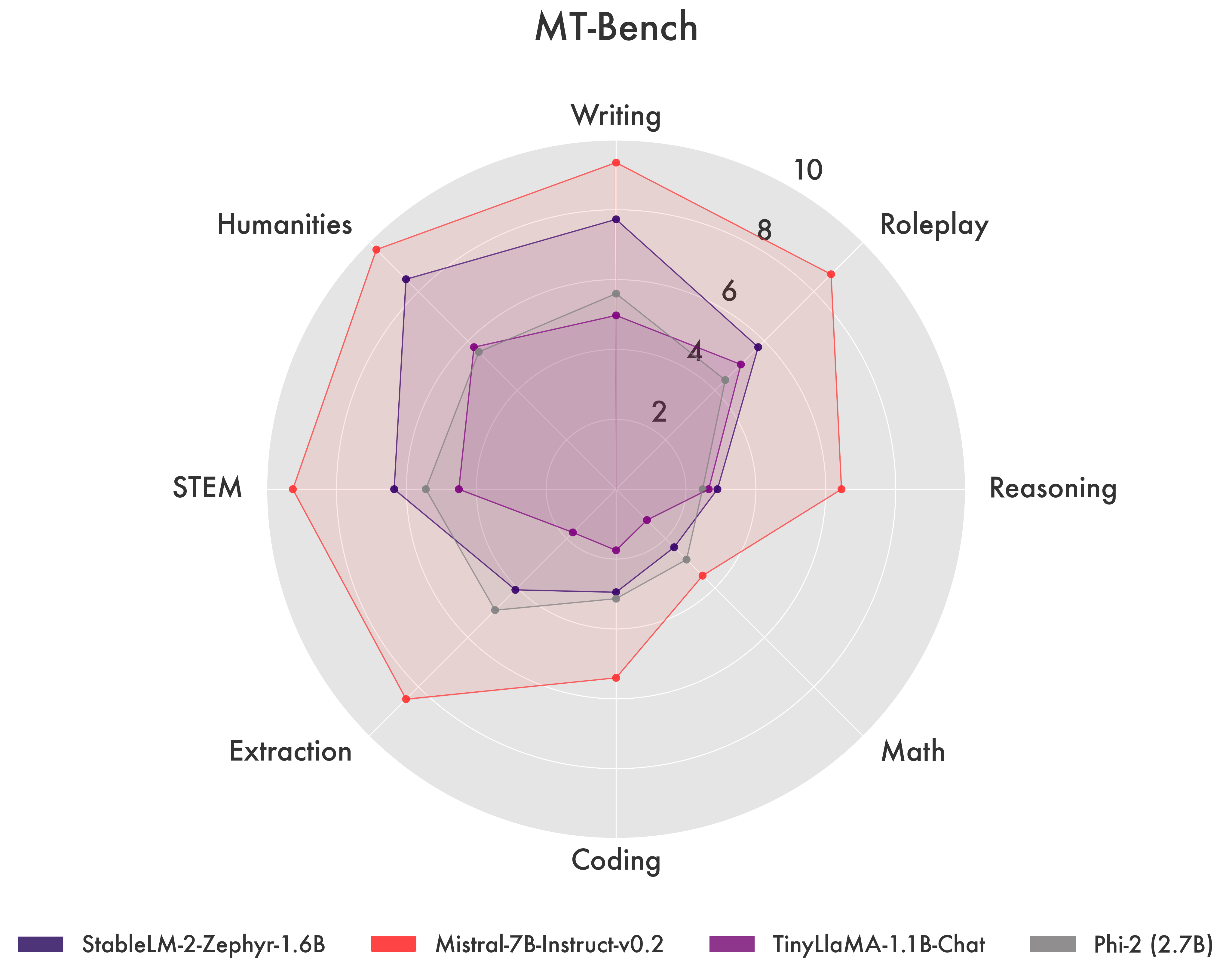
Comparing LLM capabilities across various aspects. Source.
- Rubric: Set of scores (these maybe ordinal values as well, e.g., Good, Average and Bad) defined in terms of combination of criteria. Common examples are essay-grading rubrics such as this.
[AG] - Evaluating rubrics is where LLMs provide a significant and definitive advantage wrt scalability over (a) human-annotation, and (b) fine-tuned models. This is especially true where rubrics might change at short notice, which is not uncommon in industrial settings, e.g., “For the next week, all customers must be informed of our <NEW CAMPAIGN>.”. There is no time to collect data to fine-tune a model, and the change itself is short-lived, so there is a question of how much effort must be invested; the ability to just prompt a model seems like a godsend.
Let’s look at the result next. As mentioned earlier, there are two kinds here: absolute measure and relative preference. Here’s the image from the Prometheus 2 paper again - note the results this time:
Two kinds of results. Source.
It is to be noted that in either case the result can be on a spectrum, i.e., on a continuous scale for direct assessment, or the extent by which A is better than B (or not). Of course, these might be binned later, e.g., “A is better”, for easy consumption.
Often we want the results to be accompanied by a “rationale” - this provides insight into the results, makes the user trust the results ([AG] - is this always a good thing?) and possibly acts as a chain-of-thought, which helps the LLM produce accurate results in the first place.
[AG] - I would also add good Uncertainty Quantification (UQ) to the list of things we want in the result, i.e., mention a confidence or confidence bounds. See Prediction-powered Inference (Angelopoulos et al., 2023) as an example. In fact, this can often make design easier because you don’t have to worry about results being blindly misread as much. It makes usage safer. To me, good UQ is a means for graceful degradation. It is great design if you can make it happen.
How do we Evaluate?
So, who does the evaluations? This is “\(F()\)” in the formulation. We have three options:
- Computation-based Metrics, e.g., cosine similarity, BERTScore (Zhang* et al., 2020).
- Humans. This is considered to be the gold-standard.
- LLMs. Usually referred to as LLM-as-Judge or LLM-as-Critic or AutoRater. The last term was used in the remaining talk.
Let’s look at them one at a time.
Computation-based Metrics
Computation-based metrics are cheap to utilize (usually these are heuristics or small models) and thus are conveniently scalable. These can be lexicon-based, such as ROUGE (Lin, 2004) or BLEU (Papineni et al., 2002), which look at overlap of characters. Or they might be semantic - such as BERTScore or BARTScore (Yuan et al., 2021) - which compare embeddings of the texts, to determine commonality in meaning. The presenter called out that for lexicon-based metrics, a good practice is to preprocess text to remove artifacts such as spaces, punctuation, etc., since they can have surprising effects on the scores.
[AG] - Lexicon-based similarities have been around for a long time, since they are useful in cases where information is (expected to be) extracted from text, such as in extractive summarization. Such systems predate good language synthesis, e.g., abstractive summarization, and hence these metrics also predate metrics based on semantic similarity. They are still useful in cases where enterprise policy dictates certain phrases show up in text, or in response to a technical question you’d want particular product names to show up.
While they are fast to compute, in general, they offer poor alignment to human judgement. For ex., look at comparisons of ROUGE-L (a ROUGE variant), BARTScore and BERTScore against human evaluations in the table below. This is from the G-Eval paper (Liu et al., 2023), and the metrics reported are Spearman’s correlation \(\rho\) and Kendall’s Tau \(\tau\):
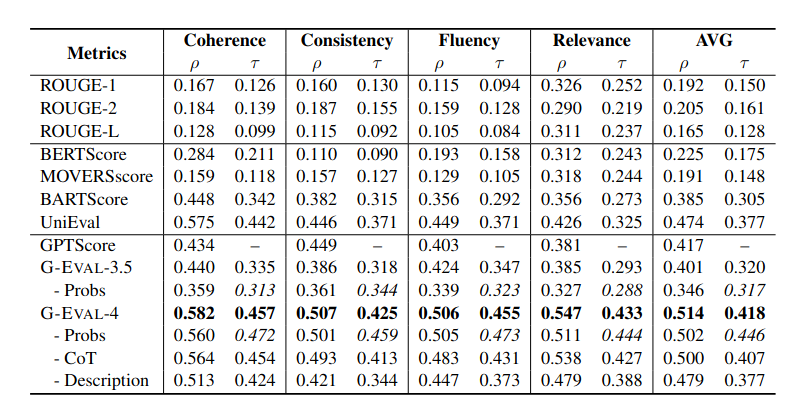
Computation-based metrics usually compare poorly against human judgement. From the G-Eval paper.
Their continued use is explained primarily by the fact that they are immensely scalable. They can be used as an approximate-but-fast indicator of quality in:
- Simple settings where you expect to find exact or similar phrases among a small set.
- Tasks that can be decomposed into simpler subtasks, e.g., to measure tool use, you can use one of these to compare function signatures, parameter names, etc.
- Low-cost sanity checking for fine-tuning. We might think of cross-entropy loss - which compares tokens - as using a simple computation-based metric.
- Setups that are complementary to the use of the other metrics. For ex., a large set of “good responses” (as per these metrics) can be identified from an even larger pool, which may then be passed off to a human for more precise annotation. Essentially it can defray the cost of expensive human annotation by serving as a filter.
[AG] - Outside of evaluations, the area of embeddings and similarity assessment have seen quite a bit of resurgence, being an integral component in the “retrieval” step of RAG. They are also useful as intermediate representations in classification or clustering tasks. In fact, my favorite way to set up a good classification baseline quickly is to use an embedding such as MPNet (Song et al., 2020) for text representation and pair it with a traditional classifier such as a Support Vector Machine (SVM).
[AG] - I think it is very important to be aware of the fact that often these metrics disagree with each other! So if you’re in a setting where these metrics might be trusted by layperson users, ensure they know of their limitations, and as a safeguard, offer multiple metrics so that they get a well-rounded view of the data. The presenter briefly touched upon this problem of incompatibility as well.
Human Annotation
This is the gold-standard evaluation, so the real focus here is on controlling the expense, which might arise due to:
- Relatively long turn-around times, i.e., this is a low bandwidth channel for evaluation.
- Cost of hiring human annotators.
- Variability in expertise: it is important to pick appropriately skilled human annotators for a task. Some options are to crowdsource, e.g., using Mechanical Turk, engage professional annotators, or find domain experts. Ensure there is inter-rater agreement.
[AG] - I find that the value of the last point above is often underestimated (may be because annotators who understand your task are hard to find, or expensive, or require training), and it takes a costly mistake (or a few) for course-correction. The bottom-line is that this should be your gold-standard, and if you fail to ensure quality in this step, there is likely no recovering later.
The presenters called out for a phased-approach where we begin with an annotation task of a few examples, so as to calibrate the judgements of the human annotators. And then, slowly scale this up. This also allows for iterative refinement of the evaluation criteria (something that was mentioned in the earlier segment of the talk).
Given the expense, the best use of human-evaluation are:
- Just before production release, to definitively certify product readiness.
- To strategically annotate data that may be used to calibrate AutoRaters.
AutoRaters
We want something that has the scalability of computation-based methods and are accurate as human evaluators. This is the realm of AutoRaters. In terms of capability of what AutoRaters may rate, they match up with humans, e.g., can provide results and rationales, work in diverse settings. The image below shows the anatomy of an AutoRater.
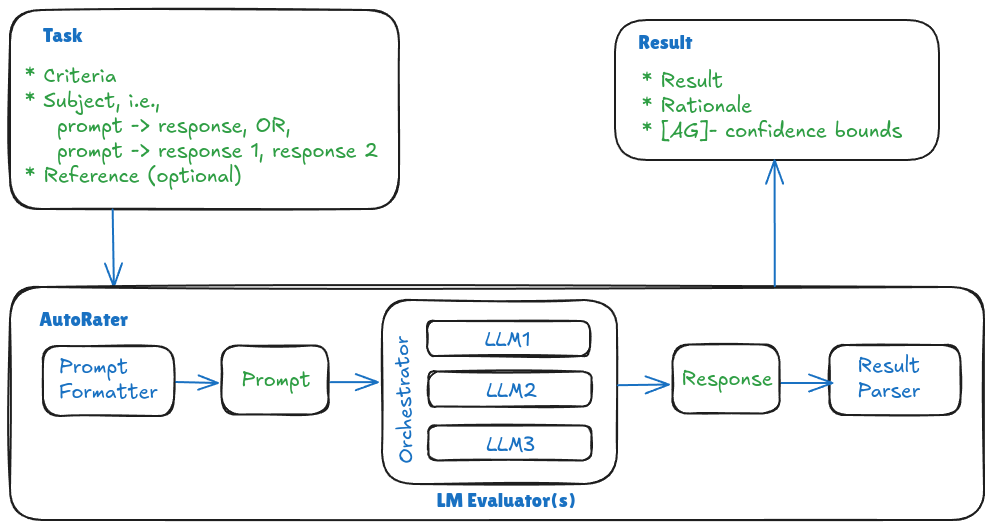
Anatomy of an AutoRater. Based on the talk slides. Stuff in green is data/information.
The key bits in the above image are:
- Task: This is the input to the AutoRater. This should have the subject, criteria, and optionally, the reference.
- Prompt Formatter: This component constructs the prompt that eventually gets fed into the evaluator language model. In building the prompt it uses the task input. It has its own high-level evaluation instructions, e.g., “You’re an expert evaluator.”, which might also contain the formatting spec for the output.
- Language Model (LM) Evaluator(s): The heart of the system. A model like GPT-4 or a model fine-tuned for evaluation such as Prometheus-2. This component may have more than one model, i.e., a panel of judges (Verga et al., 2024; Chan et al., 2024; Li et al., 2024) that collaborates to produce accurate, nuanced and unbiased judgement. Another advantage of a panel is that you might be able to perform well with small models which is cheaper than using a single LLM (Verga et al., 2024).
- Result Parser: The output from the evaluator might need specific formatting that downstream components depend on. Formatting spec might be described in the Prompt Formatter. This component ensures compliance to the specified format; [AG] - it should detect and fix malformed outputs when possible, and when not, it should at least flag such cases.
[AG] - On the topic of judgement-bias, I want to point out this interesting analysis from the G-Eval paper (Liu et al., 2023). Summaries were generated by both humans and LLMs (GPT-3.5) for some texts, and then human annotators and AutoRaters (GPT-4) were used to rate these summaries. Based on the judgement from the human annotators, three groups of these paired summaries were created:
- Where the human summary is better.
- Where the LLM summary is better.
- Where the human and LLM summaries are equally good.
These groups are shown on the x-axis in the plot below. Per group, the bars show the average scores assigned by the AutoRater to human and LLM summaries. It is easy to see that the in all cases the AutoRater prefers the LLM outputs. For ex., even in the first group, where human evaluators think that human summaries are better, the AutoRater prefers LLM summaries by a small margin.
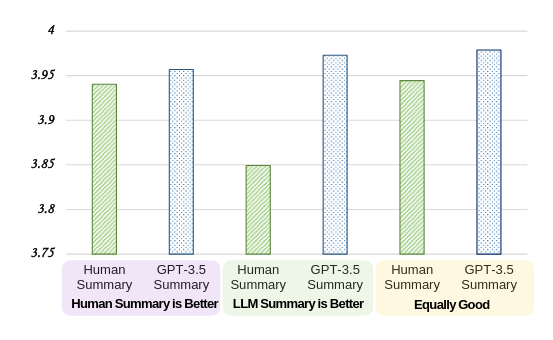
LLM judgement bias leans towards preferring LLM outputs.
RewardBench (Lambert et al., 2024) was briefly mentioned as a benchmark/leaderboard for comparing reward models (screenshot below). This is relevant because you can use rewards models as AutoRaters.
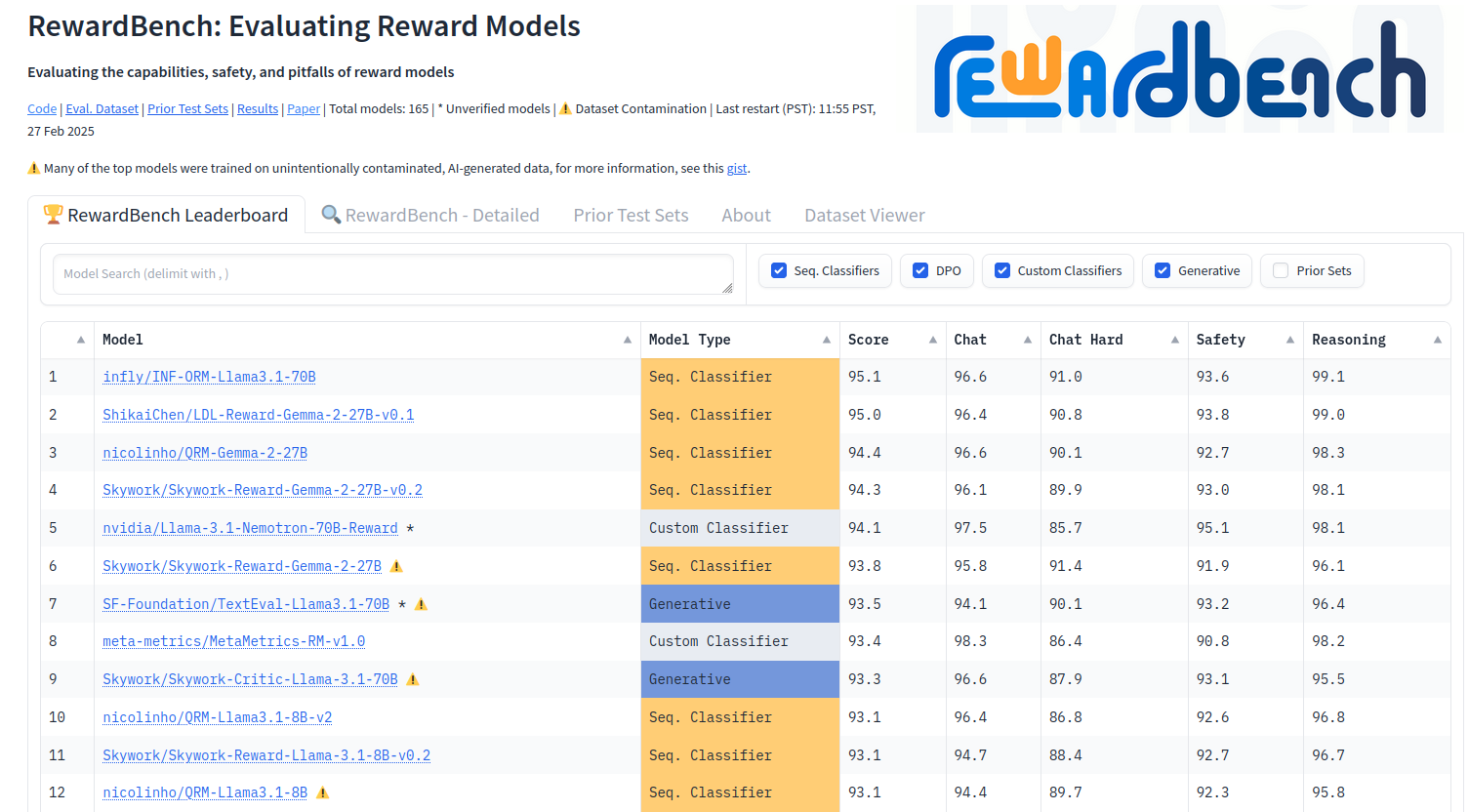
Screenshot of the RewardBench leaderboard.
[AG] - Let’s dwell on this a bit - its a slightly unusual benchmark. Reward models are an important piece of the current LLM revolution. These models are what guide LLMs to generate correct answers, at training time. These are explicit separate models in the case of Reinforcement Learning from Human Feedback (RLHF) - which was popularized by OpenAI for training the original ChatGPT. Later, a computationally-lightweight technique called Direct Preference Optimization (DPO) (Rafailov et al., 2023) became widely popular, where the LLM has an implicit notion of rewards. This benchmark directly rates this notion of rewards - explicit or implicit. In a way, it peeks behind the curtain to see why a LLM believes a certain response is a good response. Conceptually, it is measuring a simpler entity: the rewards, instead of the outcomes they lead to. Here is an article and a video by one of the co-authors that go into some detail. He also has co-authored a paper on the history of RLHF (Lambert et al., 2023). I found this other article to be succinct and helpful.
Meta-Evaluation
Meta-Evaluation is the process of validating the AutoRaters themselves. This is important - I think that no matter how amazing an AutoRater’s performance is on a public dataset, you still need to evaluate on data that’s task-specific to know if it will work for you. Production surprises are the worst kinds of surprises.
This part of the talk touched upon these aspects:
- What metrics might be used for Meta-Evaluation?
- What kind of datasets and benchmarks do we have for this?
- What’s the transferability of results on a public benchmark to your task?
- Fine-tuning for better AutoRaters.
Metrics: These are broadly of two kinds. On benchmarks where point-wise scores are provided, the common options are:
- Spearman correlation: Good for monotonic relationships, less sensitive to outliers.
- Kendall’s Tau: Suitable for ranked data and assessing concordance/discordance, handles ties well.
- Pearson correlation: Best for linear relationships with normally distributed data. [AG] - I think this is fragile for use in most cases.
[AG] - Shout out to the Chatterjee Coefficient (Chatterjee, 2021), which is a relatively new metric with some interesting properties. I should also mention that while correlation coefficients help in assessing alignment, if you are interested in exactly matching the scoring scheme of human annotators (the scores [5, 6, 7] and [1, 2, 3] are positively correlated but one is not a drop-in replacement of the other if users expect the former scale) you should also consider transforming the scores with a model; see LLM-Rubric (Hashemi et al., 2024) as an example, where a feed-forward network is used.
The other type is pair-wise scores. Here the common options are:
- Cohen’s Kappa: Measures the agreement between two raters on categorical data, accounting for chance agreement [weight=quadric]. The presenter mentioned that while there is a difference of opinion around how these scores might be interpreted, generally \(\kappa>0.8\) and \(\kappa>0.6\) are considered to be strong and moderate correlations, respectively. [AG] - “quadric” is probably a typo, and the metric being referred to likely is Quadratic Weighted Kappa (QWK); references here and here. For more than two raters, Fleiss’ Kappa is popular - but this is probably not needed here since we are comparing human annotations to those produced by LLMs.
- Confusion Matrix and accuracy are also used. [AG] - the Root Mean Squared Error (RMSE) may also be used in some circumstances (Hashemi et al., 2024).
Datasets and Benchmarks: There is a long and growing list of these. Items in the list below were briefly mentioned - most of the notes were later added by me. Note that sometimes the distinction between a dataset and a benchmark is not strong, e.g., HumanEvalPack is also considered to be a benchmark although it is listed under datasets.
Datasets:
- MT-Bench and ChatBot Arena (Zheng et al., 2023): [pair-wise] MT-bench is a series of open-ended questions (with 8 categories of user prompts) that evaluates multi-turn conversational and instruction-following ability. Chatbot Arena is a crowdsourced platform featuring anonymous battles between chatbots – users engage in conversations with two chatbots at the same time and rate their responses based on personal preferences. While these datasets have human annotations, the paper also highlights/implements AutoRaters as a proxy.
- HelpSteer (Wang et al., 2024) and HelpSteer2 (Wang et al., 2024): [pair-wise] These evaluate various aspects such as correctness, coherence, verbosity and complexity that contribute to the perceived helpfulness of responses.
- LLMBar (Zeng et al., 2024): [pair-wise] Specifically evaluates instruction following, i.e., how closely generated text adheres to a given instruction.
- AlpacaEval and AlpacaFarm (Dubois et al., 2023): [pair-wise] AlpacaFarm combines several open-source evaluation datasets and uses real-world interactions with a demo instruction-following LM as guidance for constructing this combination. AlpacaEval is AutoRater that has high agreement with human annotations.
- Anthropic Helpful & Harmless (Bai et al., 2022), and Anthropic HHH (Askell et al., 2021): [pair-wise] The former dataset contains human preferences for helpful and harmless responses, as interpreted by crowd-workers. An interesting aspect that the authors point out is that often these goals are in conflict with each other and a model that exclusively performs well on one might possibly do poorly on the other. HHH stands for “helpful, honest, and harmless”, which is an older dataset.
- “summarize from feedback” (Stiennon et al., 2020): [pair-wise] Dataset of human comparisons between summaries. Incidentally the paper is mostly about how ROUGE (a computation-based metric that we saw earlier) is not great at indicating quality of summaries, and instead a evaluator model trained with the contributed dataset does much better.
- HumanEvalPack (Muennighoff et al., 2024): [point-wise] Dataset for the coding tasks of Code Repair, Code Explanation, Code Synthesis across 6 languages. This is an extension of the HumanEval dataset. I found the paper creative in that it performs instruction tuning based on Git code commits paired with human instructions (based on this dataset).
- FLASK (Ye et al., 2024): [point-wise] Fine-grained scoring with 4 primary abilities which are divided into 12 fine-grained skills for comprehensive evaluation:
- Logical Thinking: Logical Correctness, Logical Robustness, Logical Efficiency.
- Background Knowledge: Factuality, Commonsense Understanding.
- Problem Handling: Comprehension, Insightfulness, Completeness, Metacognition.
- User Alignment: Conciseness, Readability, Harmlessness.
Benchmarks:
- RewardBench: This was discussed earlier in the section on AutoRaters.
- LLM-AggreFact (Tang et al., 2024): For testing groundedness of LLM responses against reference documents. Useful for Retrieval Augmented Generation (RAG) systems, QA systems, summarizers, etc. Aside from the dataset contribution, the paper also shows how to build small fact-checking models that are much cheaper than GPT-4 for similar accuracies.
- JudgeBench (Tan et al., 2025): Provides challenging response pairs spanning knowledge, reasoning, math, and coding.
- WildBench (Lin et al., 2024): Designed to benchmark large language models (LLMs) using challenging, real-world user queries. Consists of 1,024 examples carefully selected from over one million human-chatbot conversation logs. I would note that this benchmark itself provides AutoRated scoring (GPT-4-Turbo) but they show a high correlation with human ratings in Chatbot Arena. That might make it useful for meta-evaluation.
- EvalBiasBench (Park et al., 2024): Interesting benchmark that targets bias evaluation for judges. The authors identify following kind of biases (note that while position bias - susceptibility of a model to change judgement based on order in which responses are presented - is investigated, it is not part of the benchmark):
- Length Bias: Judge models prefer longer responses.
- Concreteness Bias: Assign credibility to responses with more details, e.g., citations.
- Empty Reference Bias: In case of an instruction that is incomplete because it is missing references, a judge should not hallucinate, and instead should ask for clarification and declare uncertainty in their response.
- Content Continuation Bias: Some models might switch to “sentence completion” mode when provided with instructions accompanied by input text.
- Nested Instruction Bias: This is an interesting one. This is bias to respond to an instruction or question embedded withing a larger instruction. For ex., in the query “Read the following sentence and suggest one correction. Are you familiar with the the US?”, the italicized portion is an embedded question. A good response might be “You might need to omit one of the adjacent ‘the’ in the sentence.”, while a bad response is “Yes, including various aspects of society and daily life.”.
- Familiar Knowledge Bias: Preference for responses that contain common knowledge, such as idioms.
- CoBBLEr (Koo et al., 2024): This also is intended to measure biases of judge models. The biases of interest here are:
- Order Bias: This is similar to the position bias mentioned in the previous point.
- Compassion Fade: Preference for responses with recognizable names.
- Egocentric Bias: Preference for a models own outputs. We discussed this behavior in the AutoRaters section in the context of the G-Eval paper.
- Salience Bias: This is the same as length bias in the previous point.
- Bandwagon Effect: Preference for a majority belief. This is similar to the familiar knowledge bias from the previous point.
- Attentional Bias: Preference for irrelevant or unimportant details. This is similar to the concreteness bias from the previous point.
Transferability to your task: Performance on the above datasets and benchmarks are only indicative of performance on your specific task. If you’re choosing a model based on public benchmarks you need to ensure the prompts and responses in the benchmark are reflective of your actual use. This is a bit tricky to do, and there is chance of suffering from both omission and commission: the cases you require may not be represented, while the overall score might be influenced by a whole host of scenarios you do not care for. Nevertheless, under tight deadlines to deliver, you might have to resort to this kind of fine-grained “problem matching”.
Ideally, you would want to human-annotate your own data - perhaps a small pool - to absolutely ensure that your AutoRaters are aligned with your business objective.
Fine-tuning of AutoRaters: OK, so you know that your AutoRater stands to improve, and may be you have some annotated data as well. What next? You could fine-tune your AutoRater to become better at your task. I won’t go into details, but here’s an image from the talk’s slides showing some fine-tuned AutoRaters. The “Type” column shows what kind of result a model produces, e.g., a discriminative model produces (preference) scores, while a generative model produces a textual response. [AG] - Just to get an idea of how powerful targeted fine-tuning can be here, the model in the first row, FLAMe-24B (Vu et al., 2024), beats GPT-4o in its overall score on RewardBench.
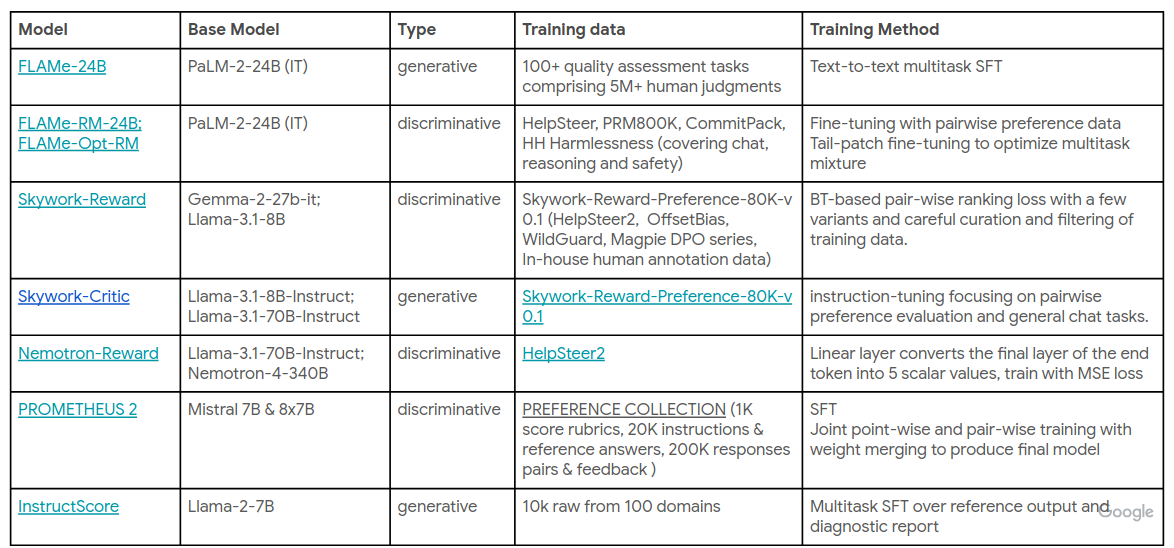
Some fine-tuned AutoRaters. From the tutorial's slides.
Limitations and Mitigation
AutoRaters potentially suffer from both issues of bias and consistency. Some common biases are preference for long responses (which we have earlier referred to as salience bias and length bias), dependence on position of some artifact in the prompt (we’ve encountered this too: position bias or order bias) and egocentric bias (we have encountered this before both in the Benchmarks and the AutoRater sections). We have seen some others as well, in the discussion on Datasets and Benchmarks. Consistency refers to the fact that AutoRater outputs may vary based on (minor) changes in a prompt or just due to pure randomness.
As mitigation the presenter suggested the strategies:
- Swapping positions of responses to detect position bias.
- Call the AutoRater multiple times to verify self-consistency. [AG] - this is also a good way to determine semantic uncertainty (Kuhn et al., 2023).
- Use a panel of diverse (i.e., originating from different model families) models (Verga et al., 2024).
- Good demonstration as part of the prompt, i.e., in-context learning.
- Fine-tune on de-biasing datasets such as the ones for EvalBiasBench (Park et al., 2024) and CoBBLEr (Koo et al., 2024), which we encountered earlier.
Summary
We looked at three kinds of evaluators:
- Computation-based metrics.
- Human Annotation.
- AutoRaters.
Each come with their pros and cons. In practice, at a high-level, we need to be mindful of the following:
- Choose between evaluators:
- The right trade-off between cost and quality based on the task.
- Utilize the fact that these types of evaluations might be complementary. For ex., during model training it is common to use a computation-based metric ensure that we do not end up with surprisingly bad model. When the model reaches a good regime, picking between its checkpoints can be done by an AutoRater. And finally, human annotators might be involved to validate production readiness. [AG] - the other example of this is of course, that the human evaluators prepare a small but high-quality pool of annotations, which may then be used to calibrate an AutoRater.
- Customize your AutoRater via:
- Prompt-engineering.
- Fine-tuning.
- Calibrate:
- Align with system or business objectives.
- Align with the domain and judging criteria.
- De-bias.
I quite agreed with the presenter when she said “we want to carry a mindset of evaluation-based development”.
Conclusion
This section is not from the tutorial - these are my opinions. Let’s ask a fundamental question: can we do without AutoRaters? Should we invest time in understanding the paradigm better?
In response, here is a plot from the paper that introduced Dynabench (Kiela et al., 2021), a model benchmarking framework. Each line denotes a task, e.g., MNIST. The y-axis shows how the competence of AI/ML techniques have evolved over time for a task; this is normalized at -1 when the task was introduced, and human performance - shown with the black horizontal line - is normalized at 0. A curve going above this line indicates the some AI/ML method has outperformed humans.
Consider this plot for a while.
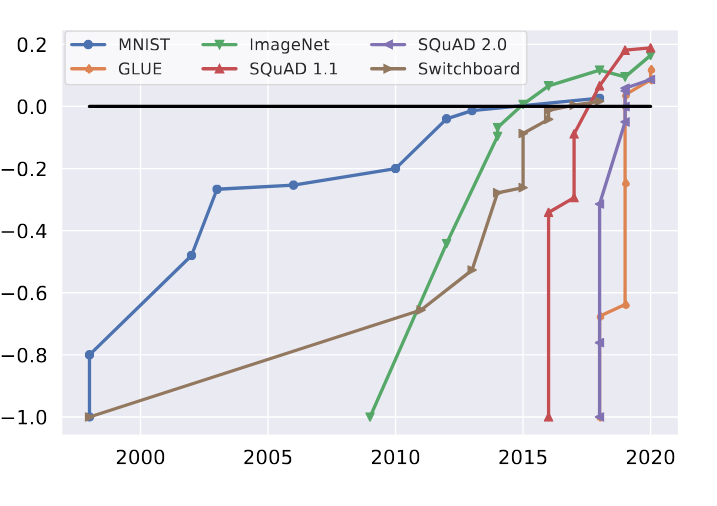
The time to overtake humans on a benchmark has been decreasing!
Note that:
- For all tasks, human performance has been surpassed.
- The time to surpass human-level performance is growing increasingly shorter.
More than anything else, the above graph (which I first encountered in this talk) tells me that AutoRating is going to catch up to human-level annotation soon, and given its scalability, it is well on its way to be indispensable in LLM-based system evaluations. In other words, I think it is here to stay.
Right now the area is messy. Multiple techniques, different suggested best practices, a new technique emerging probably every week. I think these are the teething troubles of a new area. Like it or not, if you are in the AI/ML industry, very likely you do not have the option to stand back now and comfortably re-enter the field when it has matured. What makes it worthwhile to participate, or be an active audience, in its development is the general trend seen in the plot above. At least some of these techniques are going to stick around; so some of our learnings are going to be useful for a while.
Something that was out of scope for the talk was techniques for evaluation of RAG-based systems (although the LLM-AggreFact (Tang et al., 2024) benchmark was mentioned). These are probably the most common form of LLM-based systems out there today, and not surprisingly, there is an urgent need to evaluate such systems in a way that is cheap and accurate. It is an active area of research, and some techniques are RAGAs (Es et al., 2024), RAGChecker (Ru et al., 2024) and ARES (Saad-Falcon et al., 2023).
Anyway, many thanks to the presenters for the great tutorial! Not only was it thought-provoking, but also I ended up learning a bunch of new things and got a look at the bigger picture.
References
- Dunlap, L., Mandal, K., Darrell, T., Steinhardt, J., & Gonzalez, J. E. (2025). VibeCheck: Discover and Quantify Qualitative Differences in Large Language Models. The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=acxHV6werE
- Kim, T. S., Lee, Y., Shin, J., Kim, Y.-H., & Kim, J. (2024). EvalLM: Interactive Evaluation of Large Language Model Prompts on User-Defined Criteria. https://doi.org/10.1145/3613904.3642216
- Shankar, S., Zamfirescu-Pereira, J. D., Hartmann, B., Parameswaran, A., & Arawjo, I. (2024). Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences. https://doi.org/10.1145/3654777.3676450
- Kim, S., Suk, J., Longpre, S., Lin, B. Y., Shin, J., Welleck, S., Neubig, G., Lee, M., Lee, K., & Seo, M. (2024). Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. In Y. Al-Onaizan, M. Bansal, & Y.-N. Chen (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 4334–4353). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.emnlp-main.248
- Angelopoulos, A. N., Bates, S., Fannjiang, C., Jordan, M. I., & Zrnic, T. (2023). Prediction-powered inference. Science, 382(6671), 669–674. https://doi.org/10.1126/science.adi6000
- Zhang*, T., Kishore*, V., Wu*, F., Weinberger, K. Q., & Artzi, Y. (2020). BERTScore: Evaluating Text Generation with BERT. International Conference on Learning Representations. https://openreview.net/forum?id=SkeHuCVFDr
- Lin, C.-Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out, 74–81. https://aclanthology.org/W04-1013/
- Papineni, K., Roukos, S., Ward, T., & Zhu, W.-J. (2002). BLEU: a method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 311–318. https://doi.org/10.3115/1073083.1073135
- Yuan, W., Neubig, G., & Liu, P. (2021). BARTSCORE: evaluating generated text as text generation. Proceedings of the 35th International Conference on Neural Information Processing Systems.
- Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., & Zhu, C. (2023). G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In H. Bouamor, J. Pino, & K. Bali (Eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 2511–2522). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.153
- Song, K., Tan, X., Qin, T., Lu, J., & Liu, T.-Y. (2020). MPNet: Masked and Permuted Pre-training for Language Understanding. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Lin (Eds.), Advances in Neural Information Processing Systems (Vol. 33, pp. 16857–16867). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2020/file/c3a690be93aa602ee2dc0ccab5b7b67e-Paper.pdf
- Verga, P., Hofstatter, S., Althammer, S., Su, Y., Piktus, A., Arkhangorodsky, A., Xu, M., White, N., & Lewis, P. (2024). Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models. https://arxiv.org/abs/2404.18796
- Chan, C.-M., Chen, W., Su, Y., Yu, J., Xue, W., Zhang, S., Fu, J., & Liu, Z. (2024). ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=FQepisCUWu
- Li, Y., Zhang, S., Wu, R., Huang, X., Chen, Y., Xu, W., Qi, G., & Min, D. (2024). MATEval: A Multi-agent Discussion Framework for Advancing Open-Ended Text Evaluation. In M. Onizuka, J.-G. Lee, Y. Tong, C. Xiao, Y. Ishikawa, S. Amer-Yahia, H. V. Jagadish, & K. Lu (Eds.), Database Systems for Advanced Applications (pp. 415–426). Springer Nature Singapore.
- Lambert, N., Pyatkin, V., Morrison, J., Miranda, L. J., Lin, B. Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., Smith, N. A., & Hajishirzi, H. (2024). RewardBench: Evaluating Reward Models for Language Modeling.
- Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Advances in Neural Information Processing Systems (Vol. 36, pp. 53728–53741). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2023/file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf
- Lambert, N., Gilbert, T. K., & Zick, T. (2023). The History and Risks of Reinforcement Learning and Human Feedback. https://arxiv.org/abs/2310.13595
- Chatterjee, S. (2021). A New Coefficient of Correlation. Journal of the American Statistical Association, 116(536), 2009–2022. https://doi.org/10.1080/01621459.2020.1758115
- Hashemi, H., Eisner, J., Rosset, C., Van Durme, B., & Kedzie, C. (2024). LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts. In L.-W. Ku, A. Martins, & V. Srikumar (Eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 13806–13834). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.745
- Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=uccHPGDlao
- Wang, Z., Dong, Y., Zeng, J., Adams, V., Sreedhar, M. N., Egert, D., Delalleau, O., Scowcroft, J., Kant, N., Swope, A., & Kuchaiev, O. (2024). HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM. In K. Duh, H. Gomez, & S. Bethard (Eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (pp. 3371–3384). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.naacl-long.185
- Wang, Z., Dong, Y., Delalleau, O., Zeng, J., Shen, G., Egert, D., Zhang, J. J., Sreedhar, M. N., & Kuchaiev, O. (2024). HelpSteer 2: Open-source dataset for training top-performing reward models. The Thirty-Eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=PvVKUFhaNy
- Zeng, Z., Yu, J., Gao, T., Meng, Y., Goyal, T., & Chen, D. (2024). Evaluating Large Language Models at Evaluating Instruction Following. International Conference on Learning Representations (ICLR).
- Dubois, Y., Li, X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P., & Hashimoto, T. (2023). AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback. Thirty-Seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=4hturzLcKX
- Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., … Kaplan, J. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. https://arxiv.org/abs/2204.05862
- Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J., … Kaplan, J. (2021). A General Language Assistant as a Laboratory for Alignment. https://arxiv.org/abs/2112.00861
- Stiennon, N., Ouyang, L., Wu, J., Ziegler, D. M., Lowe, R., Voss, C., Radford, A., Amodei, D., & Christiano, P. (2020). Learning to summarize from human feedback. Proceedings of the 34th International Conference on Neural Information Processing Systems.
- Muennighoff, N., Liu, Q., Zebaze, A. R., Zheng, Q., Hui, B., Zhuo, T. Y., Singh, S., Tang, X., Werra, L. V., & Longpre, S. (2024). OctoPack: Instruction Tuning Code Large Language Models. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=mw1PWNSWZP
- Ye, S., Kim, D., Kim, S., Hwang, H., Kim, S., Jo, Y., Thorne, J., Kim, J., & Seo, M. (2024). FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=CYmF38ysDa
- Tang, L., Laban, P., & Durrett, G. (2024). MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents. In Y. Al-Onaizan, M. Bansal, & Y.-N. Chen (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 8818–8847). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.emnlp-main.499
- Tan, S., Zhuang, S., Montgomery, K., Tang, W. Y., Cuadron, A., Wang, C., Popa, R., & Stoica, I. (2025). JudgeBench: A Benchmark for Evaluating LLM-Based Judges. The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=G0dksFayVq
- Lin, B. Y., Deng, Y., Chandu, K., Brahman, F., Ravichander, A., Pyatkin, V., Dziri, N., Bras, R. L., & Choi, Y. (2024). WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild. https://arxiv.org/abs/2406.04770
- Park, J., Jwa, S., Meiying, R., Kim, D., & Choi, S. (2024). OffsetBias: Leveraging Debiased Data for Tuning Evaluators. In Y. Al-Onaizan, M. Bansal, & Y.-N. Chen (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2024 (pp. 1043–1067). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-emnlp.57
- Koo, R., Lee, M., Raheja, V., Park, J. I., Kim, Z. M., & Kang, D. (2024). Benchmarking Cognitive Biases in Large Language Models as Evaluators. In L.-W. Ku, A. Martins, & V. Srikumar (Eds.), Findings of the Association for Computational Linguistics: ACL 2024 (pp. 517–545). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-acl.29
- Vu, T., Krishna, K., Alzubi, S., Tar, C., Faruqui, M., & Sung, Y.-H. (2024). Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation. In Y. Al-Onaizan, M. Bansal, & Y.-N. Chen (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 17086–17105). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.emnlp-main.949
- Kuhn, L., Gal, Y., & Farquhar, S. (2023). Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. The Eleventh International Conference on Learning Representations . https://openreview.net/forum?id=VD-AYtP0dve
- Kiela, D., Bartolo, M., Nie, Y., Kaushik, D., Geiger, A., Wu, Z., Vidgen, B., Prasad, G., Singh, A., Ringshia, P., Ma, Z., Thrush, T., Riedel, S., Waseem, Z., Stenetorp, P., Jia, R., Bansal, M., Potts, C., & Williams, A. (2021). Dynabench: Rethinking Benchmarking in NLP. In K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, & Y. Zhou (Eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4110–4124). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.naacl-main.324
- Es, S., James, J., Espinosa Anke, L., & Schockaert, S. (2024). RAGAs: Automated Evaluation of Retrieval Augmented Generation. In N. Aletras & O. De Clercq (Eds.), Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations (pp. 150–158). Association for Computational Linguistics. https://aclanthology.org/2024.eacl-demo.16/
- Ru, D., Qiu, L., Hu, X., Zhang, T., Shi, P., Chang, S., Jiayang, C., Wang, C., Sun, S., Li, H., Zhang, Z., Wang, B., Jiang, J., He, T., Wang, Z., Liu, P., Zhang, Y., & Zhang, Z. (2024). RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation. The Thirty-Eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=J9oefdGUuM
- Saad-Falcon, J., Khattab, O., Potts, C., & Zaharia, M. (2023). ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems.